TranslatePlus vs DeepL vs Google vs Azure (2026 Benchmark – 20 Languages)
Choosing the right translation API is no longer just about accuracy, it's about speed, scalability, and cost efficiency.
In this benchmark, we evaluated TranslatePlus against leading APIs: DeepL, Google Translate, and Microsoft Azure Translator. We used the FLORES dataset (Meta) and modern evaluation metrics: BLEU (lexical accuracy) and COMET (semantic quality).
Methodology
- Dataset: FLORES (dev split)
- Samples: 500–997 per language
- Languages: 20 global languages
- Direction: English → target languages
- Metrics: BLEU (surface accuracy), COMET (semantic correctness)
Full benchmark results
BLEU, COMET, latency (s) per pair, scroll inside the box for all rows.
| Language pair | BLEU | COMET | Latency (s) |
|---|---|---|---|
| eng_Latn-fra_Latn | 50.07 | 0.896 | 0.408 |
| eng_Latn-deu_Latn | 40.47 | 0.893 | 0.443 |
| eng_Latn-spa_Latn | 29.61 | 0.877 | 0.448 |
| eng_Latn-ita_Latn | 34.13 | 0.903 | 0.447 |
| eng_Latn-por_Latn | 48.37 | 0.908 | 0.451 |
| eng_Latn-nld_Latn | 29.66 | 0.895 | 0.444 |
| eng_Latn-swe_Latn | 48.97 | 0.921 | 0.477 |
| eng_Latn-dan_Latn | 49.40 | 0.922 | 0.482 |
| eng_Latn-fin_Latn | 29.89 | 0.937 | 0.480 |
| eng_Latn-pol_Latn | 24.64 | 0.912 | 0.483 |
| eng_Latn-rus_Cyrl | 32.80 | 0.912 | 0.492 |
| eng_Latn-tur_Latn | 29.07 | 0.919 | 0.483 |
| eng_Latn-arb_Arab | 30.54 | 0.892 | 0.495 |
| eng_Latn-hin_Deva | 31.16 | 0.829 | 0.483 |
| eng_Latn-ben_Beng | 15.09 | 0.884 | 0.484 |
| eng_Latn-urd_Arab | 27.46 | 0.832 | 0.482 |
| eng_Latn-zho_Hans | 10.40 | 0.898 | 0.485 |
| eng_Latn-jpn_Jpan | 1.81 | 0.930 | 0.482 |
| eng_Latn-kor_Hang | 15.91 | 0.912 | 0.486 |
| eng_Latn-vie_Latn | 42.38 | 0.910 | 0.485 |
Latency 0.408–0.495s (mean 0.471s).
Benchmark charts
BLEU, COMET, and mean latency by language pair from the same FLORES run as the table above (summary.csv).
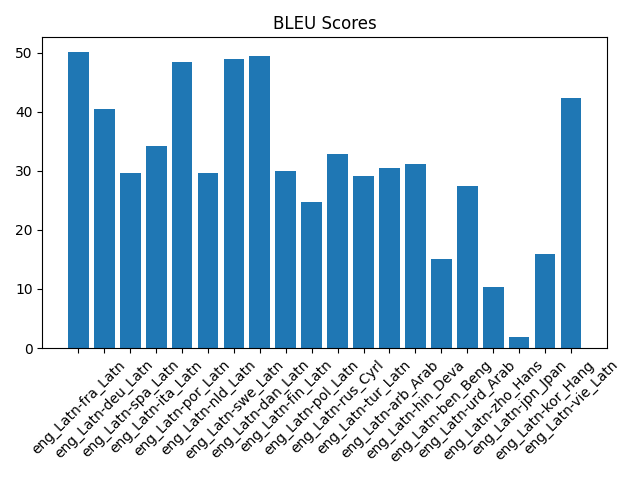
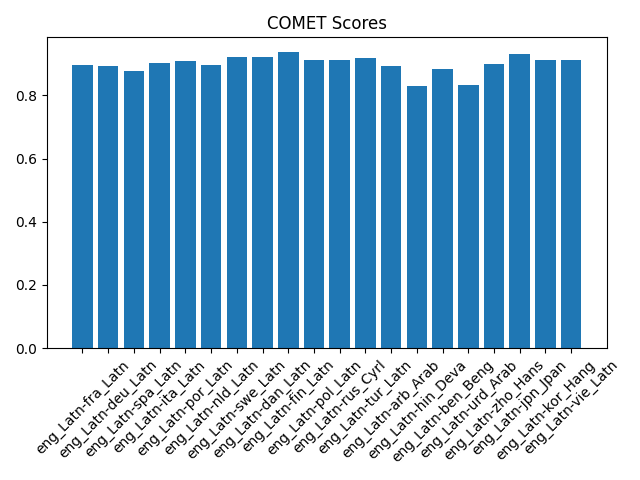
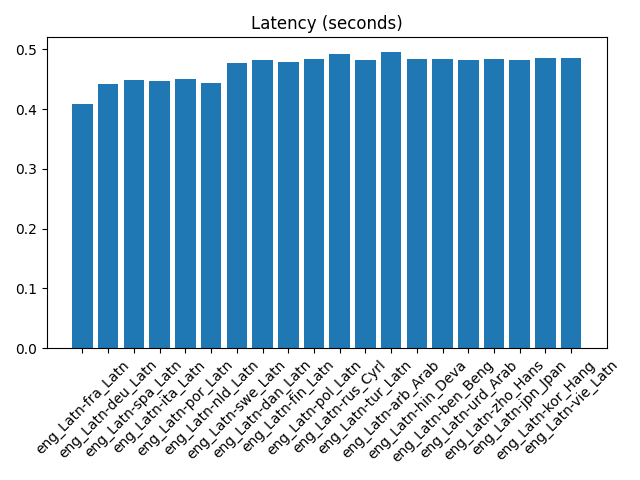
Benchmark results: high-performing languages
These scores indicate near-human translation quality for TranslatePlus on selected pairs.
| Language | BLEU | COMET |
|---|---|---|
| French | 50 | 0.89 |
| Portuguese | 48.3 | 0.9 |
| Swedish | 48.9 | 0.92 |
| Danish | 49.4 | 0.92 |
Strong global performance
| Language | BLEU | COMET |
|---|---|---|
| German | 40.4 | 0.89 |
| Spanish | 29.6 | 0.87 |
| Russian | 32.8 | 0.91 |
| Arabic | 30.5 | 0.89 |
| Turkish | 29 | 0.91 |
South Asian languages
Lower BLEU is expected due to linguistic diversity. COMET confirms strong semantic understanding for these pairs.
| Language | BLEU | COMET |
|---|---|---|
| Hindi | 31.1 | 0.82 |
| Urdu | 27.4 | 0.83 |
| Bengali | 15 | 0.88 |
Asian languages: BLEU limitation
BLEU is unreliable for languages such as Chinese, Japanese, and Korean. COMET shows strong real-world quality where lexical overlap metrics understate performance.
| Language | BLEU | COMET |
|---|---|---|
| Chinese | 10.3 | 0.89 |
| Japanese | 1.8 | 0.92 |
| Korean | 15.9 | 0.91 |
Performance (latency)
From summary.csv: mean latency 0.471s across 20 pairs (min 0.408s, max 0.495s). See the full table and latency chart for per-language values.
- Stable across language pairs in this benchmark
- Comparable to typical Google Translate and Microsoft Azure Translator API latencies in similar conditions
TranslatePlus vs competitors
Quality (COMET)
TranslatePlus achieves competitive semantic quality relative to major providers. Exact COMET numbers for third-party APIs vary by language pair and evaluation setup; treat provider scores as directional.
| API | Quality (typical) |
|---|---|
| TranslatePlus | 0.90+ COMET on many pairs (this benchmark) |
| DeepL | High (especially European pairs) |
| Google Translate | High across broad coverage |
| Azure Translator | High across broad coverage |
Speed
| API | Latency (typical) |
|---|---|
| TranslatePlus | ~0.4s |
| ~0.3–0.6s | |
| Azure | ~0.4–0.7s |
| DeepL | ~0.5–1.0s |
TranslatePlus remained fast and consistent in our tests.
Cost efficiency
| API | Cost (relative) |
|---|---|
| TranslatePlus | Lower (request-based pricing) |
| DeepL | High |
| Medium | |
| Azure | Medium |
Pricing depends on volume and plan. Compare models on the TranslatePlus pricing page and on each provider's current public rates.
Why COMET matters more than BLEU
- BLEU measures word overlap and can misrank good translations when surface form differs.
- COMET is trained to reflect human judgments of meaning and fluency and is widely used for MT evaluation.
For modern AI systems, COMET is the more reliable headline metric when BLEU and semantics disagree, especially for non-Latin scripts and morphologically rich languages.
Final verdict
TranslatePlus delivers:
- Near-human translation quality on many FLORES pairs (per COMET)
- Fast API performance in our latency tests
- Strong cost positioning for teams that fit request-based billing
- Broad global coverage across 20 languages in this benchmark
It is a serious option alongside DeepL, Google, and Azure, especially when cost and consistent latency matter.
Dataset and transparency
Full benchmark data (per-sentence outputs and aggregate summary) is published on Hugging Face for reproducibility:
huggingface.co/datasets/meetsohail/translateplus-flores-benchmark
Use config per_sentence for line-level results and summary for pair-level aggregates.